RNN 原理
naive version
以Sentiment Analysis(情感分析)为例
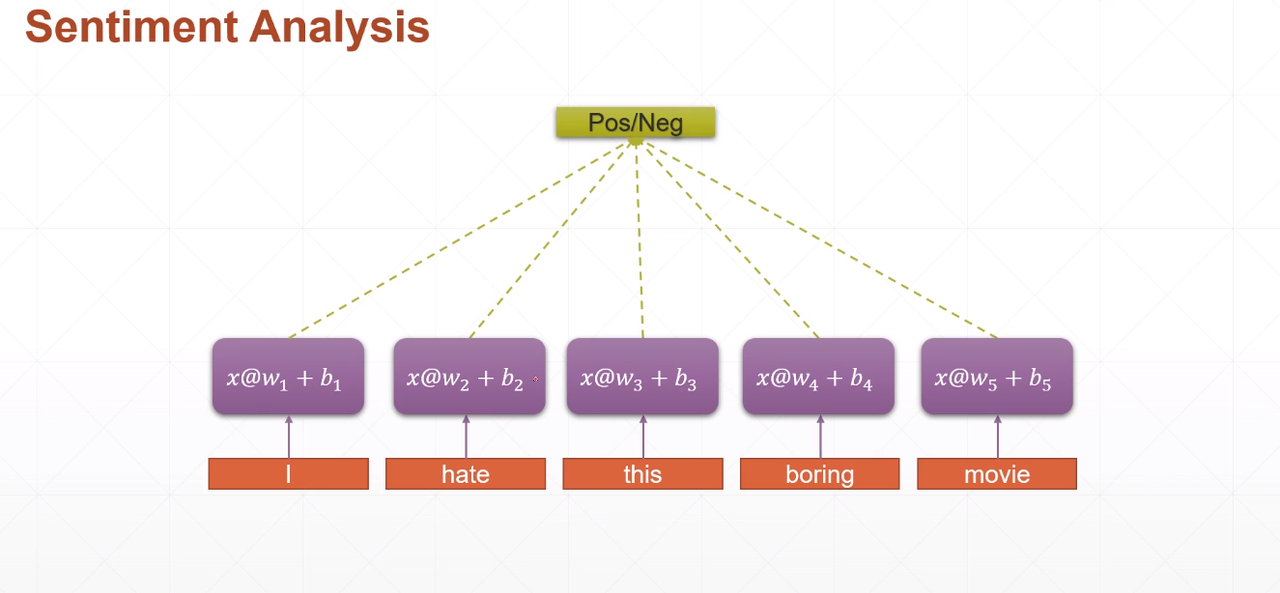
对每个单词进行word embedding, 假设embedding dim=100。
则 i hate this boring movie 就可以表示为$[ 5,100]$的矩阵。
最naive 的做法就说对每个单词(100维的tensor) 用一个线性层Linear layer: $x@w_i+b_i$ 来进行特征抽取(降维)。则每个线性层输出维度为 $[2]$, 合并后的维度为$[5,2]$,最后再接个线性单元做二分类(pos/neg)。问题基本解决。
这样做法存在的问题
long sentence
- 100+ words
- too much paramers $[w,b]$
no context information
- consistent tensor
没有上下文信息是非常不智能的,比如不喜欢分词后为不,喜欢,喜欢这个positve 类型的词前接了一个否定词不,则语义立即反转。
- consistent tensor
Weight Sharing
我们希望权值共享,以求减少网络参数量,这样就可以处理更长的句子。那怎么做呢?我们可以对所有的 input 用一个$[w,b]$来处理。如下图所示,本来5个$w_1,…,w_5$、$b_1,…,b_5$减少为1个$w$,$b$。
意思就是$x@w+b$不再是抽取特定位置单词特征的线性层,而是可以对所有输入的单词进行特征抽取。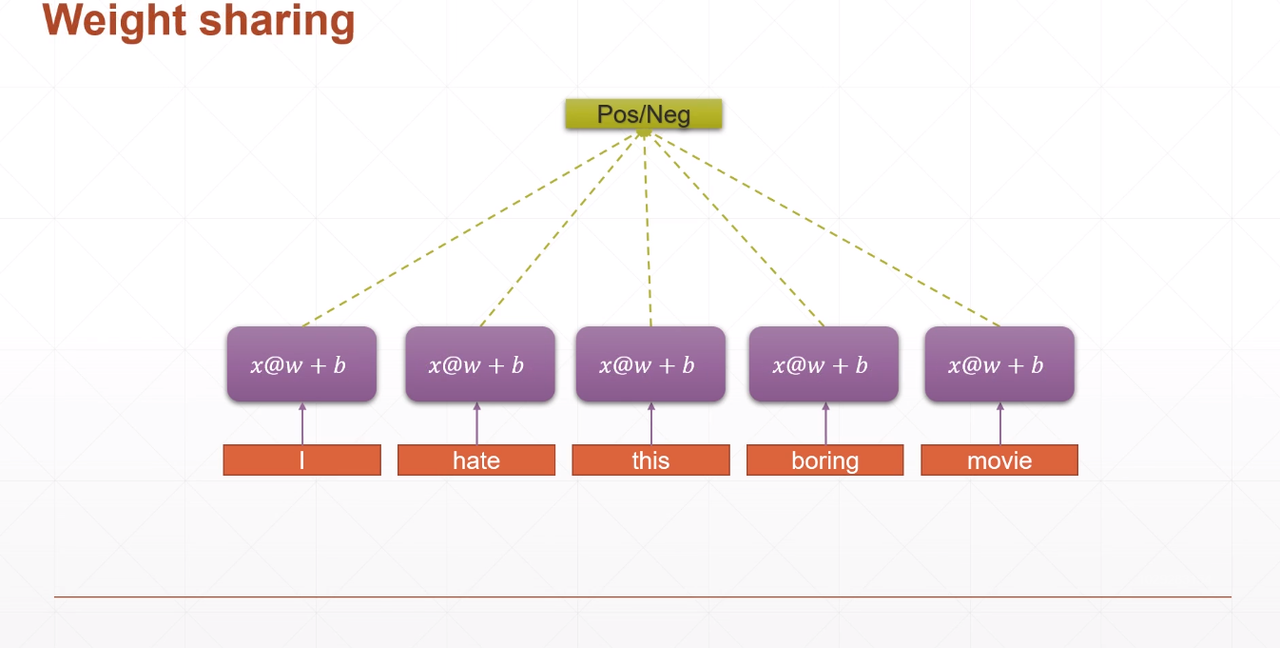
Consisten memory
怎么来记忆上下文语境信息呢?看到开心应该也要看到开心这个词的前面还有个不,不能离散的对每个词进行处理。所以这里我们必须需要这样的一个记忆单元,他们持续贯穿你的整个语境。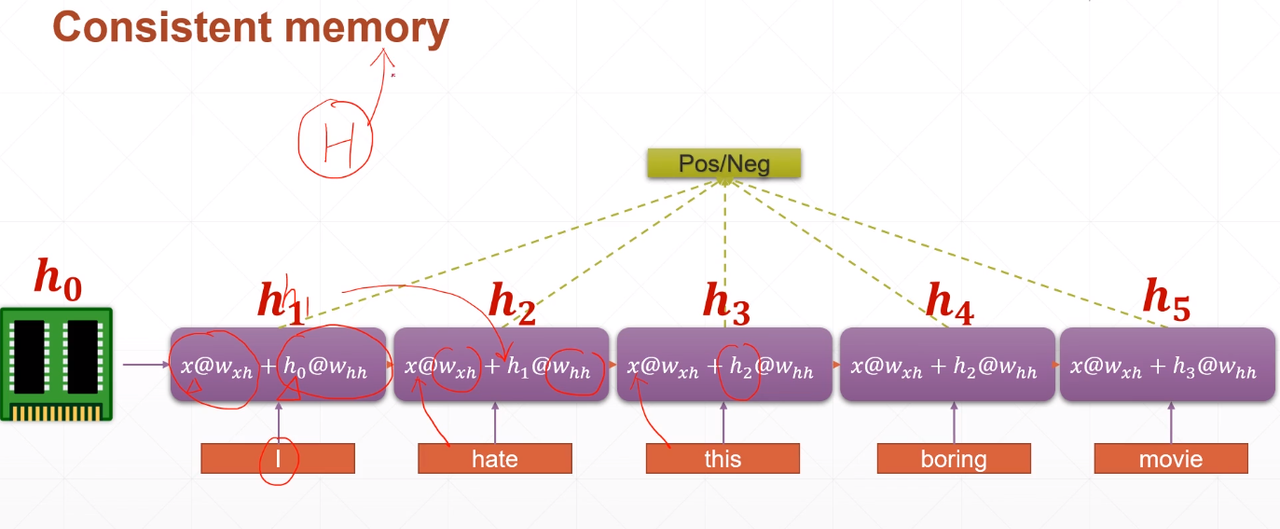
$h_0$
初始 记忆单元 memory$x@w_{xh}+h_i@w_{hh}$
$w_{xh}$对当前 input 进行特征提取,可以理解为考虑当前语境信息。
$h_i@w_{hh}$,对上一记忆单元(初始记忆单元)进行特征提取,可以立即为考虑前面的语境信息。folded model:
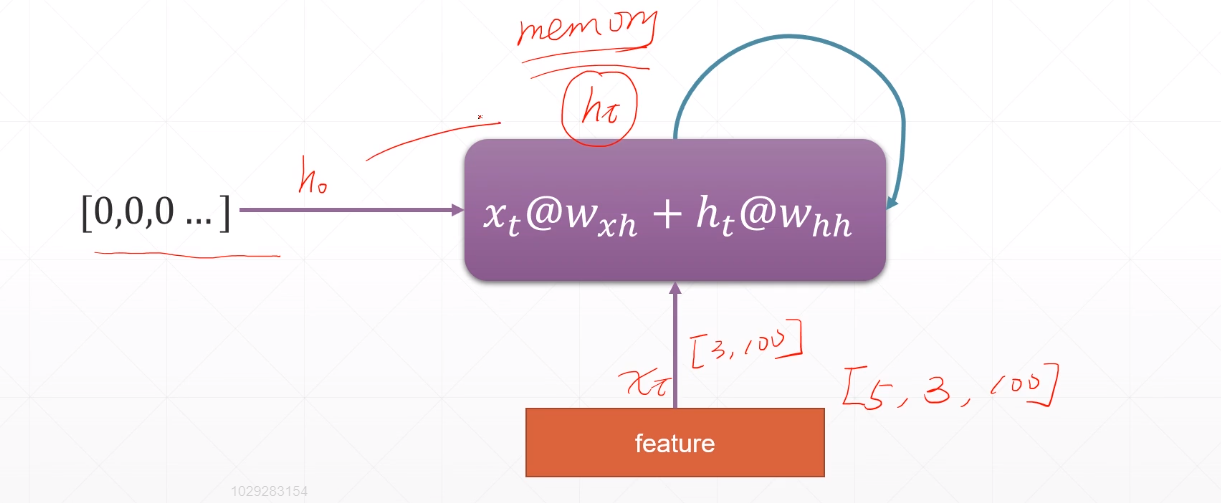
unfolded model
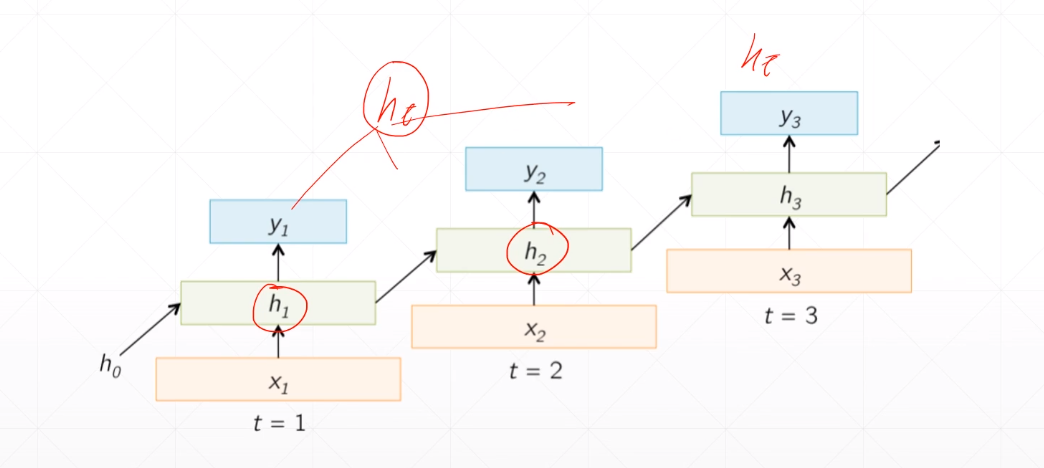
模型最终输出依赖最后一个$h_t$还是综合$h_1$,$h_2$,…,$h_t$,你可以自由组合决定。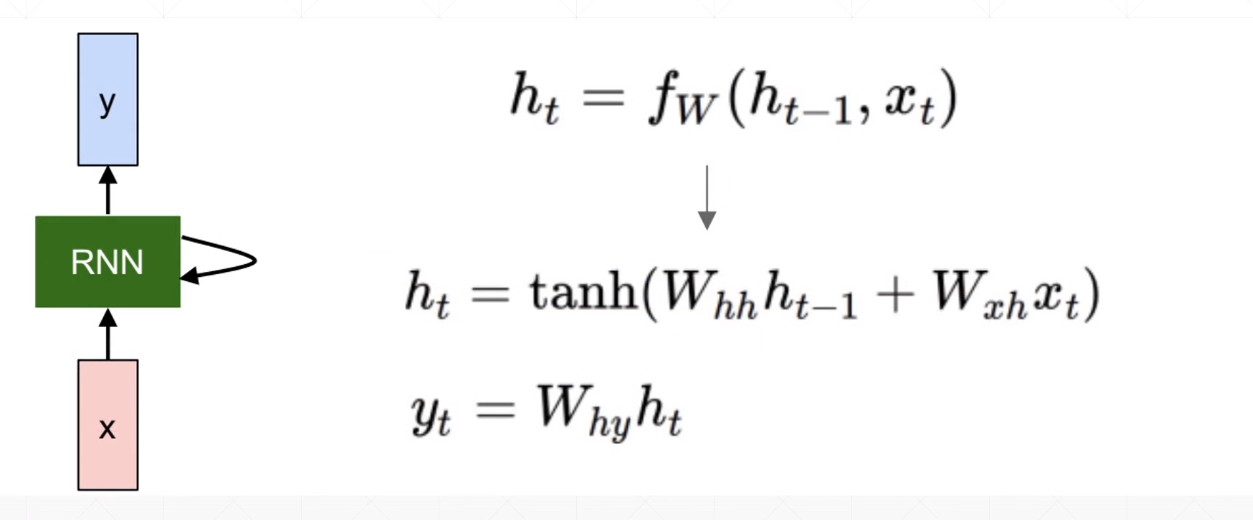
note: $tanh取值范围为$-1$到$1$ ,$y_t = W_{hy}h_t$ 对当前时刻的 memory 进行一个线性变化输出。
How to train
$$h_t = tanh(W_{hx}x_t+W_{hh}h_{t-1})$$
$$y_t = W_Oh_t$$
$$\frac{\partial E_t}{\partial W_{hh}} =\frac{\partial E_t}{\partial W_{hh}^0}+
\frac{\partial E_t}{\partial W_{hh}^1} +…+\frac{\partial E_t}{\partial W_{hh}^t} $$
$$ =\sum^{t}{i=0} \frac{\partial E_t}{\partial y_t}\frac{\partial y_t}{\partial h_t}\frac{\partial h_t}{\partial h_i}\frac{\partial h_i}{\partial W{hh}}$$